
Kullandığımız birçok araç ve servis, göz önünde olan kullanıcı arayüzlerinin hemen arkasında duran yapı, aslında yıllar süren teorik araştırmaların ve deneysel çalışmaların ürünü olan algoritmalara dayanır. Üzerine sorgular hazırlatıp aratma yaptığınız alanların arkasında farklı teknikler bulunuyor. Çünkü veriyi nasıl getirdiğiniz kadar veriyi nasıl sakladığınız da çok önemli. Arama motorlarının temelinde yatan veri yapısı ve sıralama yöntemleri, “inverted index” ve TF-IDF tekniklerine dayanıyor. Bunları anlamak için örnekler yapacağız.
“Elasticsearch in Action” kitabında daha detaylı izah edilmiş. Ayrıca dileyenler Elastic.co blog üzerinden de bu tekniği anlamak için gözgezdirebilir: https://www.elastic.co/blog/found-elasticsearch-from-the-bottom-up
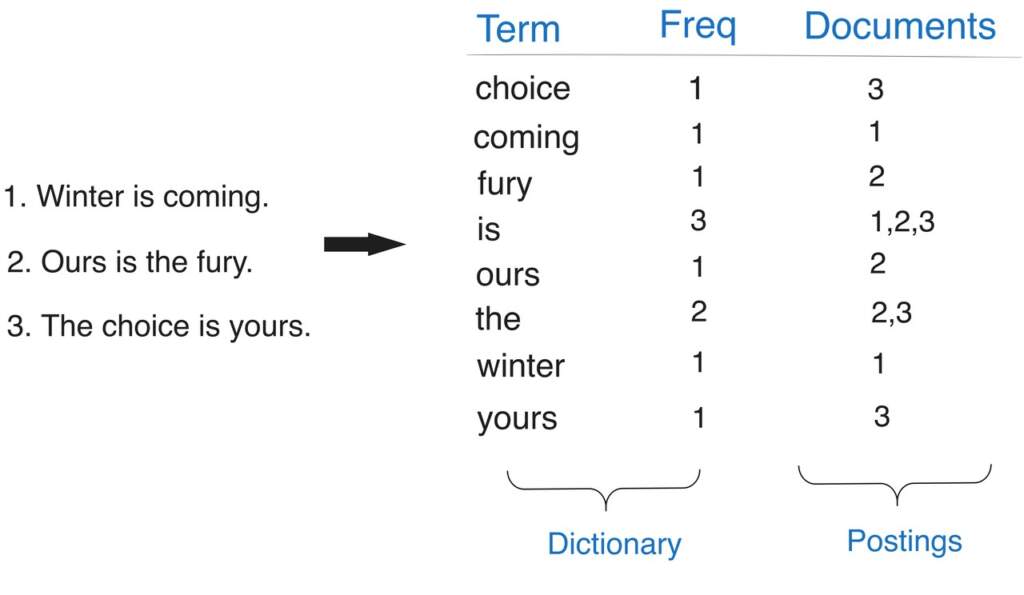
Arama problemini basitçe tarif edelim. Özellikle hukuk alanında emsal kararlar, mevzuatlar ve yönetmelikler üzerine çok fazla veriyle çalıştığım için buralardan örnek vermek istiyorum. Elimizde büyük miktarda metin (doküman koleksiyonu) ve kullanıcıdan gelen kısa sorgular var. Amacımız ise gelen sorguya en uygun dokümanları hızlı şekilde döndürebilmek. Her dokümanı baştan sona taramak küçük sayıda olan veri kümesinde çalışsa da, gerçek dünyada tekrarlı ve düşük gecikmeli sorgularda asla pratik değildir. Bunun yerine metinleri “indekslemek” yani arama için önceden işlenmiş bir veri yapısına dönüştürmek gerekir. “Inverted index” bu amaç için kullanılan temel yapıdır.
Inverted index yapısının oluşturulması temel olarak şu adımlardan geçer:
Tokenizasyon: Girdi yani metin, arama yapılabilir birimlere (token) bölünür. Bu işlem kelime bazlı olabilir veya dil kurallarına göre daha gelişmiş ayrıştırma içerir.
Normalizasyon: Token verileri ortak bir forma getirilir. Büyük/küçük harf dönüştürme, noktalama temizliği, diakritik kaldırma ve Unicode normalizasyonu bu aşamaya dahildir.
Stop-word çıkarma ve kök/lemma indirgeme: “ve”, “ile” gibi çok sık geçen ama ayırt edici olmayan token parçaları isteğe bağlı olarak çıkarılır. Ardından kelimeler kök ya da lemma hâline indirgenerek varyasyonlar tek terim altında toplanır.
Postings (terim listeleri) oluşturma: Her terim için geçtiği dokümanların ID’lerini, frekanslarını ve varsa pozisyon bilgilerini içeren bir posting list oluşturulur. Bu yapı sayesinde aramalar doküman taraması yerine doğrudan ilgili terimin listesine erişilerek çok daha hızlı yapılır.
Sıralama (ranking) için en yaygın klasik yaklaşım TF–IDF (Term Frequency – Inverse Document Frequency) ilkesidir. Temelde bir terimin bir dökümanda sık geçmesi (term frequency, tf) o döküman için o terimin önemli olduğunu gösterir ama aynı terimin koleksiyondaki hemen her dökümanda bulunması (inverse document frequency, df) onun ayırt edici gücünü azaltır.
Modern arama motorları TF–IDF’e ek olarak BM25 (Best Match 25) gibi daha iyi performans modeller veya dil modeli tabanlı skorlamalar kullanır ama yine de TF–IDF temel mekaniği bugün pek çok yöntemin anlaşılması için hala yol göstericidir.
Uygulama ve performans açısından şunları not edelim. Inverted index, index sırasında depolama gereksinimi getirir. Index oluşturma (ve güncelleme) işlemine zaman ve kaynak harcanıt fakat sorgu başına maliyet dramatik şekilde azalır. Ayrıca indeks tasarımında alanlar (title, body, anchor text vb.), pozisyon bilgisi, n-gram desteği, dil ve karakter işleme (örn. unicode, diakritik normalizasyonu) ve saklanan alanların seçimi gibi mühendislik kararları arama kalitesini doğrudan etkiler. Bu Elasticsearch içerisinde bir index için “mapping” anlamına gelir.
Sonuç olarak bir arama sisteminin görünür kısmı için temelde birçok algoritma bulunuyor. Eğer konuya derinlemesine girmek isterseniz Elasticsearch In Action kitabını okuyabilirsiniz.
Token-Based Search ve Full-Text Index Karşılaştırması
Token-based search: Metni anlamlı birimlere (token/kelime) ayırır ve aramalar bu token kümesi üzerinden yapılır. Örneğin metinde “kanunname” varsa onun sorgusunu bulur, “name”yi bulunmaz çünkü token değildir.
Full-text index: Metni karakter/byte dizileri (ör. karakter n-gram veya raw byte sequence) olarak ele alır ve tokenize işlemi yapmaz.
Bu sayede bir kelimenin ortasından veya parçalarından yapılan aramalar da bulunabilir. Uygulama olarak n-gram indeksleri, suffix array veya trigram tabanlı yaklaşımlar yaygındır. Bilhassa büyük veriler bulunan yapılarda “n-gram” gibi yaklaşımlar daha olumlu sonuçlar vermektedir. Tecrübe edildi.
Token Based Index Yapısı
Şimdi ise token based index üzerinde inverted index & TF-IDF yapılarıyla nasıl arama yapıldığını, algoritmanın nasıl çalıştığını anlamaya çalışalım. Elastic üzerinden de örnek gösterirsek daha iyi anlaşılacağını düşünüyorum.
Binary Term–Document Incidence Matrix
Matrix, koleksiyondaki terimlerin hangi dökümanlarda geçtiğini gösteren ikili (0–1) bir yapıdır. Bu matriste satırlar terimleri, sütunlar dokümanları temsil eder. Hücreye 1 yazılması terimin ilgili dokümanda yer aldığını, 0 yazılması ise yer almadığını ifade eder.
Bu matrisi oluşturmanın ilk adımı, tüm dokümanlardaki kelimeleri tokenize ederek, tekrar edenleri elerken benzersiz (distinct) bir terim kümesi elde etmektir. Bu terimler matristeki satırları oluşturur. Ardından doküman adları sütun haline getirilir. Daha sonra her terim–doküman kesişimi kontrol edilerek, terim o dokümanda bulunuyorsa 1, bulunmuyorsa 0 yazılır.
Elimizde tokenize edildiğinde şu terimleri üreten 4 döküman bulunsun:
Distinct terimler: “network”, “protocol”, “latency”, “throughput”, “packet”, “router”
Dokümanlarımız ise: “Network Basics”, “Advanced Routing”, “Protocol Design”, “System Performance”
Bu durumda matrisi doldururken örneğin “network” terimi “Network Basics” ve “System Performance” dokümanlarında geçiyorsa, ilgili hücrelere 1 yazılır.
“router” yalnızca “Advanced Routing” içinde geçiyorsa, sadece o sütunda 1, diğer tüm sütunlarda 0 olur.
Sonuç olarak elimizde N adet terim ve M adet doküman varsa, N×M boyutunda ikili bir matris elde etmiş oluruz.
Bu matris yapısıyla basit arama işlemlerini hızlı bir şekilde yapmayı sağlar. Örneğin “latency” terimini aramak istediğimizde tek yapılması gereken, “latency” satırındaki 1 değerine sahip sütunları geri döndürmektir.
Eğer iki terimin birlikte geçtiği dokümanları bulmak istiyorsak, örneğin “packet” AND “protocol”, ilgili satırların bit değerlerini AND işlemine tabi tutmak yeterlidir. Ortaya çıkan satır, her iki terimin de bulunduğu dokümanları gösterir.
Bu yapı modern arama motorlarında kullanılan inverted index kavramının temelini oluşturur. Artık döküman içinde terim aramak yerine, terimler üzerinden o terimlerin bulunduğu dokümanlara gidilir. Bu yüzden “tersine çevrilmiş indeks” adı verilmiştir.
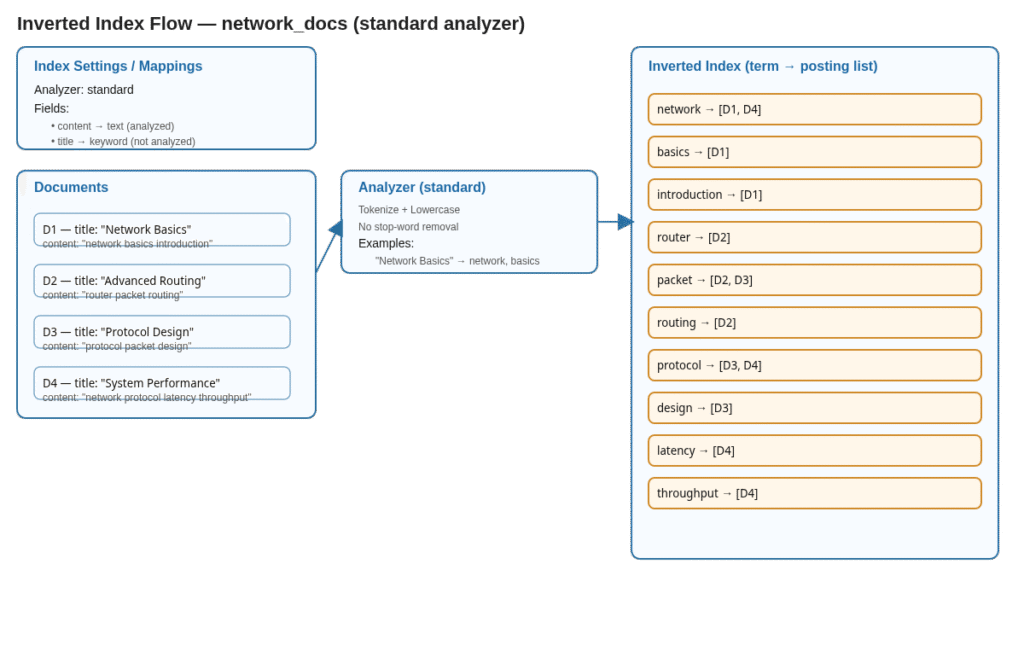
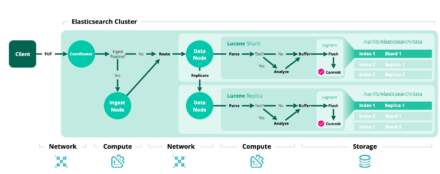
Elasticsearch ile Parallelik: Analyzer + Inverted Index
Elasticsearch aynı mantığı daha gelişmiş analizörler, pozisyon bilgisi ve scoring ile gerçekleştirir. Mapping aşamasında kullandığınız analyzer tokenizasyonu belirler ve sonrasında sistemi otomatik olarak bir inverted index oluşturur.
Index mapping:
PUT network_docs
{
"settings": {
"analysis": {
"analyzer": {
"simple_keyword_analyzer": {
"type": "standard"
}
}
}
},
"mappings": {
"properties": {
"content": {
"type": "text",
"analyzer": "simple_keyword_analyzer"
},
"title": { "type": "keyword" }
}
}
}Burada content alanı tokenize edildiği için token-based index mantığı uygulanır. ES otomatik olarak terim ve döküman listesi (inverted index) oluşturur. Yani yukarıdaki binary matrisin gelişmiş bir versiyonudur.
Dokümanlar:
POST network_docs/_bulk
{"index":{}}
{"title":"Network Basics","content":"network basics introduction"}
{"index":{}}
{"title":"Advanced Routing","content":"router packet routing"}
{"index":{}}
{"title":"Protocol Design","content":"protocol packet design"}
{"index":{}}
{"title":"System Performance","content":"network protocol latency throughput"}Bu dökümanlara dayanarak sorgular yazalım:
İki terimin birlikte aranması için sorgu örneği (bu bir binary matrix içinde AND işlemidir):
GET network_docs/_search
{
"query": {
"bool": {
"must": [
{ "match": { "content": "packet" } },
{ "match": { "content": "protocol" } }
]
}
}
}Bu örneğe ait bir şema isterseniz daha net anlaşılacağı kanaatindeyim.
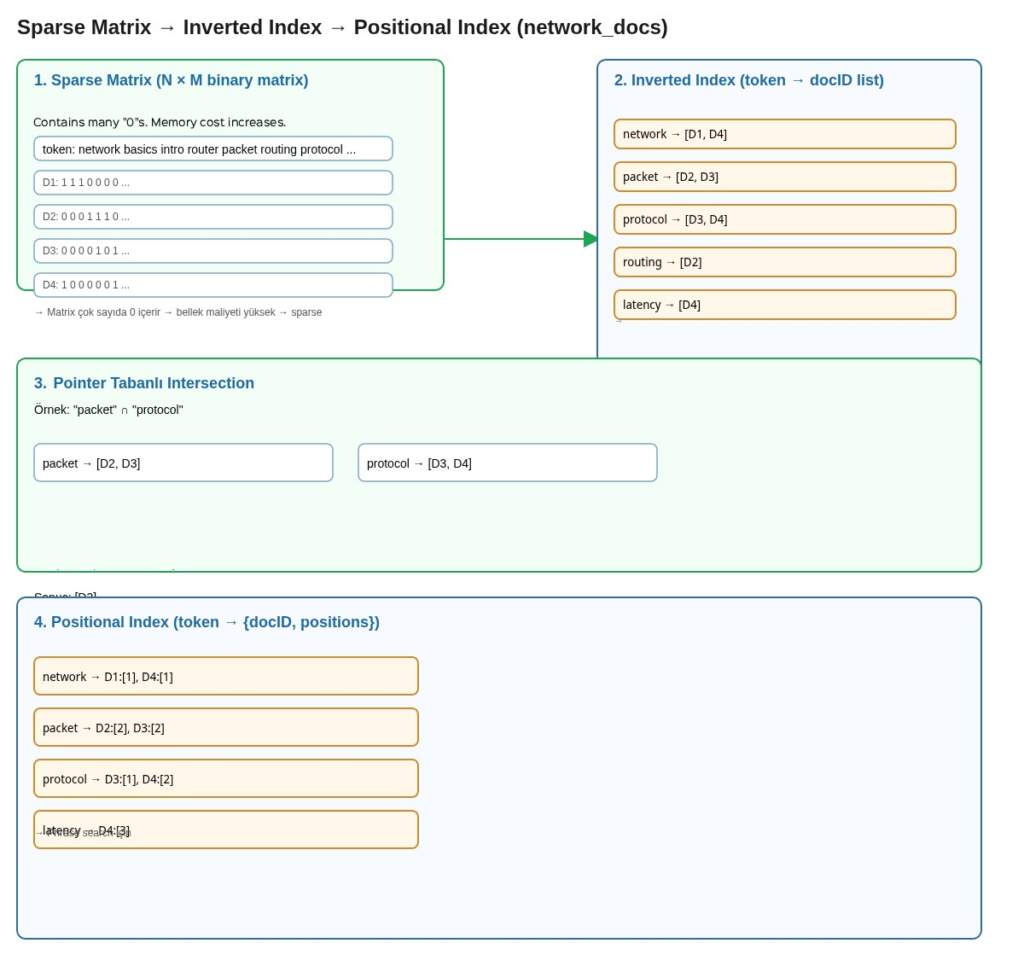
Sparse Matrix ve Inverted Index
Bahsettiğimiz yaklaşımda elimizde, döküman ve token ilişkisinin 0 ve 1’lerden oluştuğu N×M boyutunda bir binary matrix var. Bu matriste çoğu hücre 0 olacağından, yani token öğeleri sadece bazı dökümanlarda geçeceğinden, matris sparse (seyrek) yapıda olur. Bu durum hem bellekte yüksek maliyet yaratır hem de işlem performansını olumsuz etkiler.
Buna çözüm olarak, araştırmacılar matrix’i doğrudan saklamak yerine sadece her token ifadelerin geçtiği dökümanların ID listesini tutmayı tercih etmişlerdir. Böylece gereksiz 0 değerleri depolamaktan kaçınılmış ve hafıza kullanımı önemli ölçüde azaltılmıştır. Bu yapının literatürdeki adı inverted index olarak adlandırılır.
Elastic sorgularını gösterdiğim önceki örnekte bitwise matrix üzerinde iki token kesişimini bulmak için satırları AND işlemiyle birleştirmek yeterliydi. Artık token başına sorted döküman ID listeleri tuttuğumuzdan, iki token kesişimini bulmanın maliyeti linear, yani kısa olan ID listesine orantılıdır.
Inverted Index phrase search (kelime grubu araması) için yeterli değildir. Bunun için positional index yapısı geliştirilir.
Positional Index ve Inverted Index Karşılaştırması
Positional index, inverted index yapısının bir adım ötesidir. Sadece terimin geçtiği doküman ID’lerini değil, aynı zamanda her terimin doküman içindeki pozisyonlarını da tutar. Bu sayede sistem, phrase query ve proximity query (yakınlık sorgusu) gibi karmaşık sorguları destekleyebilir, yani iki veya daha fazla terimin birbirine yakın geçtiği dokümanları bulabilir.
| Terim | Doküman ID: Pozisyonlar |
|---|---|
| apple | 1: 7, 19; 2: 1, 17 |
| banana | 2: 6; 3: 14, 22 |
| cherry | 1: 3 |
Positional index biraz daha fazla depolama alanı gerektirir çünkü ek pozisyon bilgisi de tutuyor. Basit sorgularda inverted index genellikle daha hızlıdır çünkü işlenecek veri daha azdır. Positional index ise ek pozisyon bilgisi nedeniyle daha yavaş olabilir ancak karmaşık sorgular için gereklidir.
Aşağıda bir özet grafiği bulunuyor.
Arama ve Relevancy – TF-IDF
Elasticsearch, bir token arandığında sadece dökümanları döndürmekle kalmaz, relevancy skorunu (score) da hesaplar. Bu skor dokümanın aranan terimle ne kadar ilişkili olduğunu gösterir. Elastic aramayla ilgili skorlamayı size nasıl hesaplıyor?
Sistem yalnızca kelimenin geçtiği dökümanları göstermekle kalmaz, bunları önem sırasına göre (ranked) de sıralamak ister. Bu sıralama problemi relevancy problem olarak adlandırılır.
Aranan kelimemiz “aslan”.
Örnek:

TF’ye göre sıralama: D2 (4) > D1 (2) > D3 (0). Yani D2 kullanıcı için daha relevant kabul edilir. Ancak sadece TF kullanmak yetersizdir. Çok sık kullanılan kelimeler (“ve”, “ile”, “bu”) tüm dökümanlarda yüksek TF’ye sahip olabilir ve yanıltıcı olur.
IDF – Inverse Document Frequency (Ters Doküman Frekansı)
IDF bir kelimenin genel dökümanlar içindeki yaygınlığını ölçer. Amaç, çok sık kullanılan kelimelerin önemini azaltmak ve nadir kelimelere ağırlık vermektir.
Böyle formül edilir:
Toplam döküman sayısı N = 1000
“aslan” 10 dökümanda geçiyor: IDF(aslan) = log(1000/10) ≈ 2
“ve” 900 dökümanda geçiyor: IDF(ve) = log(1000/900) ≈ 0.046
Yani “aslan” aramada “ve”den çok daha değerli sayılır.
TF-IDF – Skor
TF-IDF bir terimin dökümandaki frekansı ile nadirliğini birleştirir.
Formül: TF-IDF(t,d)=TF(t,d)×IDF(t)
Örnek:
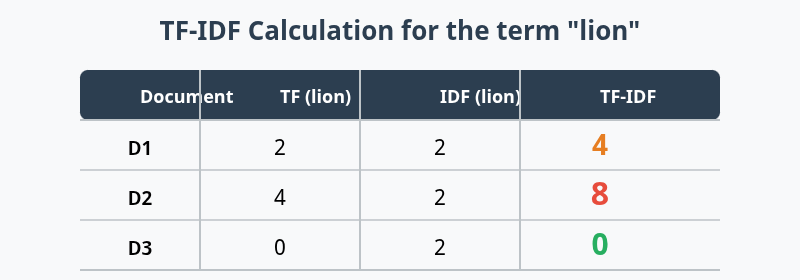
Sonuç: D2 > D1 > D3
TF-IDF yapısı sayesinde arama motorları en alakalı belgesi en üstte gösterilir.
Gerçekten teknik bir konu ama anlaşılması hiç zor değil. Günlük kullandığımız bir Elastic sorgusunun nasıl çalıştığını böyle algoritmaları görerek bilirseniz, hangi sorguyu nerede ve nasıl kullanmanız gerektiğini daha iyi anlamış olacaksınız.


Yorum bırakın