
Mikroservis mimarisine geçildiğinde sadece servisler değil, problemler de dağıtık hale gelir. Her servisin kendi veritabanı şemasına sahip olması, tek bir iş akışını tamamlamak için birden fazla servis ve dolayısıyla birden fazla veritabanı çağrısı yapılmasını zorunlu kılar.
Bu durum performans maliyetinin yanında asıl kritik konu olan “veri tutarlılığı (consistency)” konusunu gündeme getiriyor. Artık tek bir veritabanı üzerinde kontrol edilen bir işlemden değil, ağ üzerinden haberleşen bağımsız bileşenlerin ortak bir sonuca ulaşmasından bahsediyoruz.
Microservice mimarisinde tutarlılık (consistency), iki farklı uçta çalışan servislerin aynı sonucu üretmesi anlamına gelir. Burada tutarlılık sorunu birkaç şekilde doğabilir.
Senkronizasyon Problemleri
Bir işlemin başlatılmasıyla sonucun alınması arasında geçen sürede, veri senkronizasyonu (yani tüm servislerin güncellenmesi) sağlanamazsa, örneğin bir serviste yapılan güncelleme diğer servislere ulaşmazsa tutarsız sonuçlar elde edilir.
Özellikle microservice sistemlerde veritabanı şemalarının farklı olması, farklı uygulama veya servislerin aynı bilgiyi farklı şekillerde tutmasına neden olabilir. Bu durumda “bounded context” ortaya çıkar. Bounded context (sınırlı bağlam), bir işlemin başlatıldığı sırada ilgili tüm bağlamların işlem yapılacak alanlar veya arayüzler) aynı anda erişilebilir olmaması durumudur. Yani bir işlem başlatıldığında bu işleme ait tüm kaynaklar henüz hazır olmayabilir veya bazıları o anda erişilemez durumda olabilir.
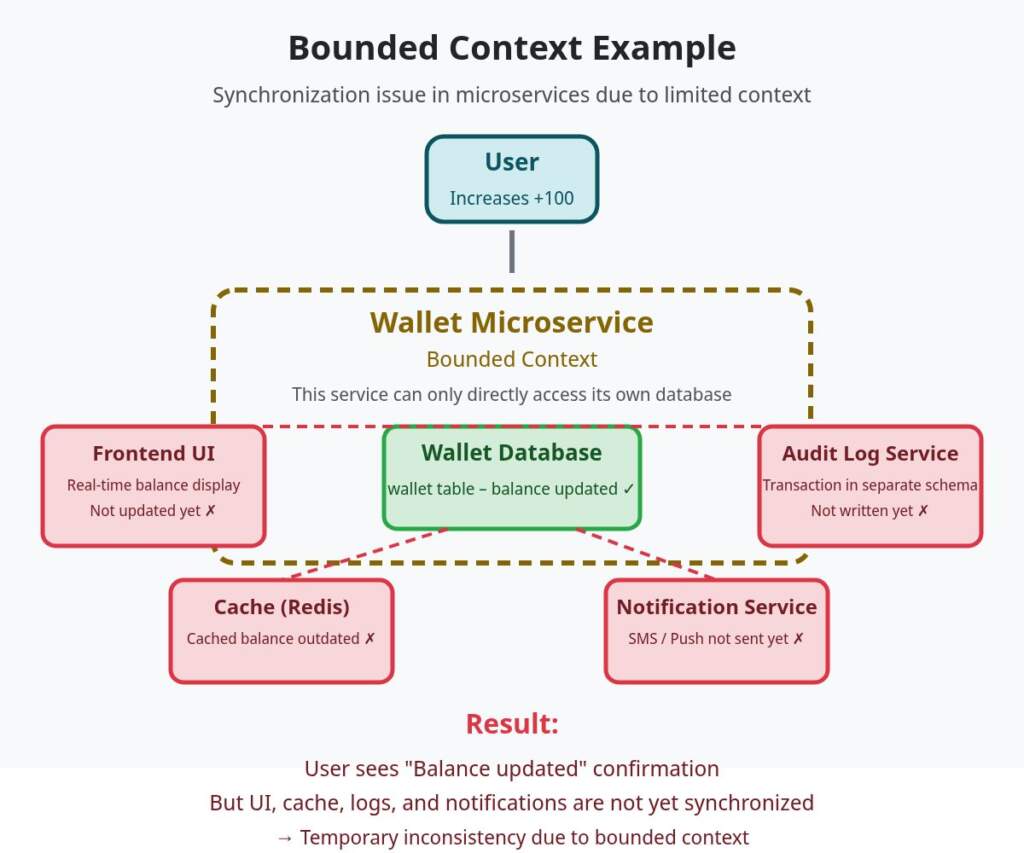
Bir API’de cüzdan güncelleme işlemi başlatıldığını düşünelim. Güncelleme yapılacak veritabanı ve kullanıcı arayüzü gibi kaynaklar aynı anda erişilebilir değil. Eğer sistemde “wallet” ve “update_deposit” tabloları farklı şemalarda ve başka tablolar üzerinde tutuluyorsa işlem başladığında sistem bazı verileri göremez ya da güncelleyemez. Kullanıcı bakiyesinin güncellendiğini sanırken, aslında veritabanı güncellenmemiştir ve kullanıcı beklemeye alınır.
ACID Kavramı ve Transaction Yönetimi
Her bir transaction klasik olarak bu tutarlılık problemini çözen temel yapılardır. ACID prensipleri sayesinde bir işlem dizisinin ya tamamen başarılı olması ya da tamamen geri alınması garanti edilir. Örneğin bir create işleminden sonra birden fazla update yapılacaksa, bu güncellemelerden biri başarısız olduğunda tüm işlemler rollback edilir. Dağıtık bir mimari üzerinde çalışırken “inconsistent state” oluşmasını önlemek ve işlemleri güvenle yürütmek için transaction kullanmak şarttır. Tutarlılık ve güvenilirlik getirir.
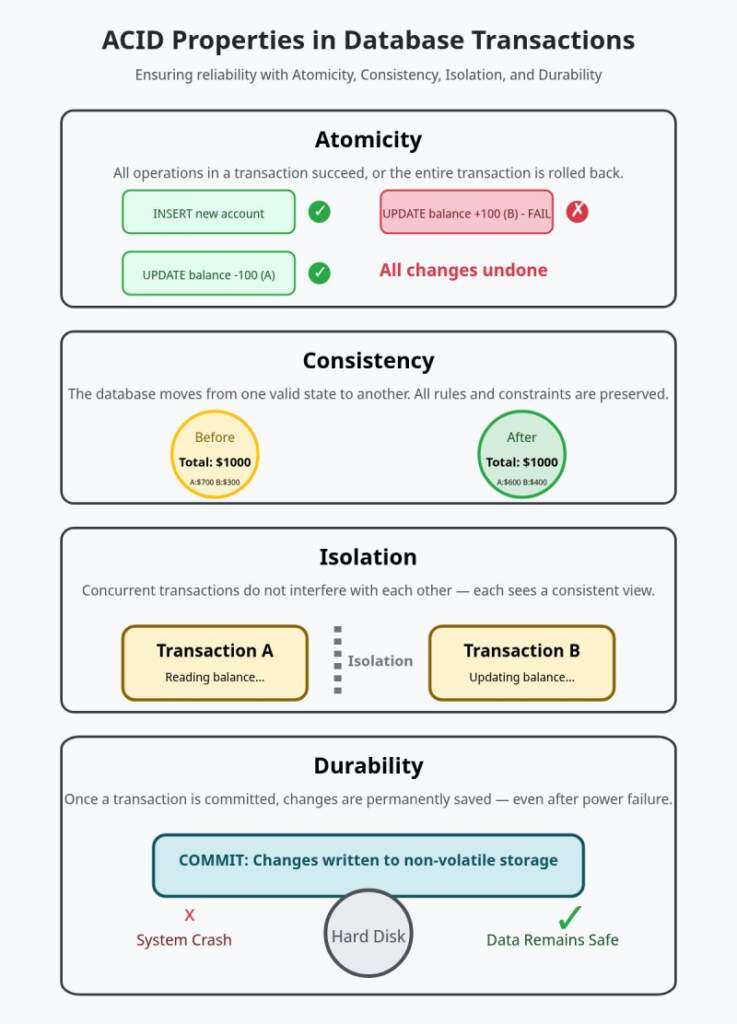
Atomicity: Ya hep ya hiç. Tüm işlemler başarılı olur veya hiçbiri uygulanmaz (rollback). İşlemler atomiktir yani tek bir iş parçacığı tüm işlemleri aynı anda yürütebilir.
Consistency: Veritabanı tutarlı durumdan tutarlı duruma geçer. Tüm operasyonların tutarlı şekilde yürütülmesi sağlanır, aksi durumda rollback olur.
Isolation: Eşzamanlı transaction öğeleri birbirini etkilemez. Sistemdeki diğer işlemlerden izole ediliriz yani yapılan işlemler başka süreçlerden etkilenmez.
Durability: Başarılı işlem kalıcı olarak kaydedilir. Bir değişiklik kalıcı olur ve geri alınamaz.
Bu dört ilke ile ya her işlem çalışır ya da hiçbiri çalışmaz şeklinde güvenli bir “ya hep ya hiç” garantisi verilir. ACID prensipleri özellikle monolith (tek bir veri kaynağına sahip) mimarilerde geçerlidir. Çünkü tüm işlemler aynı veri kaynağı üzerinden yürütülür. Tek bir kaynak olduğu için işlemler tutarlı olur.
Ama microservice mimaride (örneğin birden fazla farklı servis ve veritabanı kullandığında), her bir servis veya veritabanı farklı bir kaynaktır. Burada ACID ilkeleri bozuluyor.
Servisler ve veritabanları ayrıldığında bu konfor ortadan kalkıyor. Çünkü her servis kendi yaşam döngüsüne ve çoğu zaman kendi transaction yönetimine sahiptir. Bu noktada distributed transaction problemi ortaya çıkar.
Bir örnekle açıklayalım.Veritabanına sipariş vardır (order service aracılığıyla) ama ürünün süresi uzamamıştır (product service tarafında update sorunu olmuştur). Klasik rollback şansı yok çünkü order service işlemi kendi bölümünde commit etmiş. Sorunumuz tam olarak bu: Bir adım başarılı olduktan sonra sonraki adım başarısız olursa ne yapacağız?
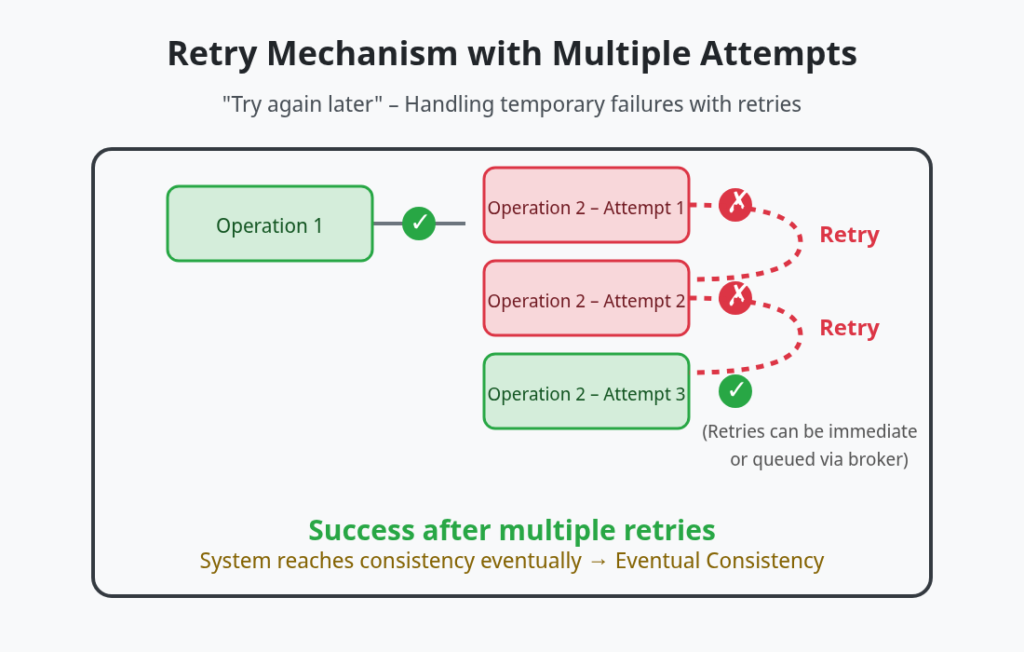
Retry
Bu yaklaşımda bir işlem başarılı olduktan sonra diğerinde hata oluşursa, başarısız olan operasyon hemen vazgeçilmez ve tekrar denenir. Retry işlemi senkron şekilde arka arkaya yapılabileceği gibi çoğu gerçekçi senaryoda işlemi bir queue (message broker vb.) içine alıp yeniden denemek için de uygulanır. Bu işlemin amacı geçici hatalar (network problemi, kısa süreli servis kesintisi, timeout) ortadan kalktığında işlemi başarıyla tamamlamaktır.
Başarısız bir update istekte şöyle bir queue örneği olabilir:
{
"event": "BalanceUpdateRequested",
"orderId": "ORD-123",
"amount": 200,
"retryCount": 0
}“Try again later” yaklaşımı bizi doğrudan eventual consistency modeline taşır. Bu modelde sistemin her an tutarlı olması beklenmez. Yeterli zaman tanındığında sistemin tutarlı hale gelmesi hedeflenir. Bu yaklaşım basit görünse de, transaction yapısının bize sunduğu güçlü tutarlılık garantisini kaybettirir ve sistemi bilinçli olarak tutarsız bir duruma sokar. Dolayısıyla pek hoş bir yöntem olarak görülmez ve daha kontrollü dağıtık transaction yaklaşımlarına (örneğin Saga pattern) geçmek gerekir.
Distributed Transaction
Distributed transactions genelde dağıtık yapıdaki transactional süreçleri yönetilebilir kılma yaklaşımına dayanır. Temelde amaç monolitik transaction’da olduğu gibi, dağıtık yapıdaki transaction verilerini tutarlı halde tutmaktır. En çok adı geçen iki transaction yönetimi olan Two Phase Commit (2PC) ve Saga Pattern’den bahsedeceğim. Bunların yanında Retry-After-Failure, Object Storage Monitoring gibi çözümler de mevcut.
Two Phase Commit (2PC)
2PC dağıtık sistemlerde birden fazla servis veya veritabanı üzerinde yapılan işlemlerin tek bir transaction gibi davranmasını sağlamaya çalışan klasik bir distributed transaction protokolüdür. Bu yaklaşımda merkezi bir Transaction Manager (Coordinator) bulunur ve tüm katılımcılar (participants) bu manager tarafından yönetilir. Amacı ise tüm katılımcıların ya birlikte commit etmesi ya da herhangi bir hata durumunda birlikte rollback etmesidir.
İki fazlı çalışma mantığı (prepare & commit) bulunuyor. İlk faz olan Prepare (Voting) Phase’de coordinator, tüm transaction katılımcılarına “commit etmeye hazır mısın?” sorusunu sorar. Katılımcılar bu aşamada gerekli kontrolleri yapar. Kaynakları lock durumuna getirri ve “hazırım” ya da “hazır değilim” şeklinde yanıt verir. Tüm katılımcılardan olumlu cevap gelirse ikinci faza geçilir. İkinci faz olan Commit Phase içinde coordinator, commit kararını yayınlar ve katılımcılar işlemleri kalıcı olarak diske yazar.
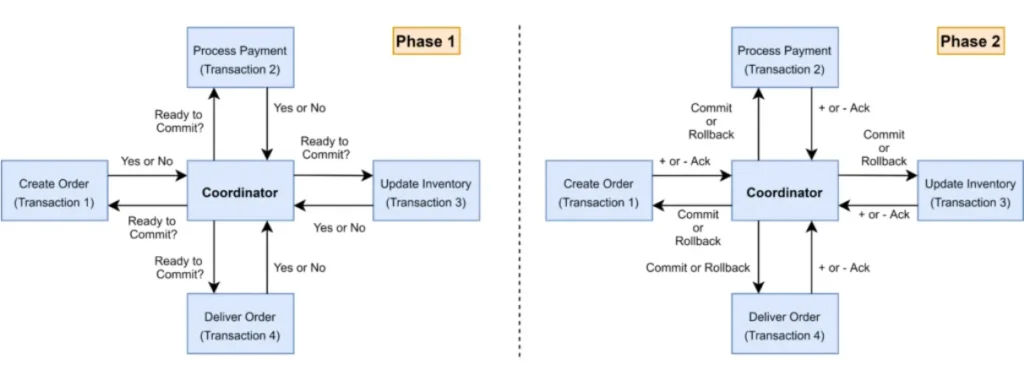
2PC’nin en büyük avantajı, dağıtık ortamda atomiklik sağlamaya çalışmasıdır. Yani order ve product gibi farklı servisler tek başına karar veremezler. Merkezi bir karar mekanizmasına bağlı olarak commit eder. Bu açıkça klasik retry yaklaşımlarına kıyasla çok daha güçlü bir tutarlılık modelidir.
Örnek verelim, OrderService ve DepositService bir 2PC transaction yapısına katılır. Transaction Manager önce her iki servise prepare isteği gönderir. OrderDB “order insert başarılı ve commit için hazırım” der. DepositDB “bakiyeden düşülebilir hazırım” derse coordinator commit kararı alır ve her iki tarafa commit mesajı gönderir. Eğer DepositDB prepare aşamasında “bakiye yetersiz” hatası dönerse coordinator her iki servise rollback mesajı yollar ve sistem tutarlı kalır.
Dezavantajları da bulunuyor. 2PC teoride güçlü olsa da pratikte ciddi maliyetler doğurabilir.
Performans problemi: Prepare aşamasında katılımcılar kaynaklara lock uyguladığı için transaction süresi uzadıkça bu kaynaklar kullanılamaz hale gelir. Özellikle long-running transaction varsa bir servisin yavaş cevap vermesi ve diğer tüm servislerin de beklemesine neden olur.
Yavaş katılımcı problemi: Örneğin DepositService, dışarıda bir bankacılık API’sine bağlı ve prepare cevabı 5 saniye sürüyor. Bu süre boyunca OrderDB ve DepositDB lock altında bekler. Bu sırada başka siparişler aynı tabloları kullanamaz. Sonuç olarak sistem teknik olarak tutarlı ama pratikte yavaş ve kilitli hale gelir.
Blocking davranışı: En zayıf noktalarından biri blocking protocol olmasıdır. Transaction Manager çökerse veya bir katılımcı prepare aşamasından sonra cevap veremez hale gelirse, transaction belirsiz bir durumda kalır. Katılımcılar commit mi rollback mi yapacaklarını bilemez ve lock durumu da kalkmaz. Bu da sistemin bir kısmının tamamen bloke olmasına yol açar.
Coordinator çökmesi: Prepare fazı tamamlanmış ve herkes “hazırım” demiştir. Coordinator commit mesajını göndermeden çökerse katılımcılar kararsız kalır. Commit mi edecekler yoksa rollback mi? Protokol gereği beklemek zorundadırlar. Bu sırada veriler kilitli kalır ve sistem ilerleyemez.
Two Phase Commit protokolü dağıtık transaction problemini çözmeye çalışan güçlü yaklaşımlardan biridir ancak yüksek latency, düşük availability, blocking davranışı ve failure senaryolarındaki kırılganlığı nedeniyle modern mikroservis mimarilerinde nadiren tercih edilir. Bu yüzden yerini çoğu zaman Saga gibi daha esnek, eventual consistency tabanlı modellere bırakmıştır.
2PC Nerelerde Kullanılır?
2PC’nin yaygın olarak düşünüldüğü veya kullanıldığı bazı farklı senaryolar vardır:
Bankalar arası para transferi (örneğin SWIFT işlemleri): Bir hesaptan para düşerken diğer hesapta artması aynı anda olmalı yani biri başarılı olup diğeri başarısız olursa ciddi maddi kayıp oluşur.
Rezervasyon sistemleri (uçak bileti + otel + araç kiralama): Bir seyahat acentesinin birden fazla sağlayıcıyla (farklı veritabanları) çalıştığı durumlarda, tüm rezervasyonların ya hep birlikte onaylanması ya da hiçbiri yapılmaması gerekir.
Dağıtık veritabanlarında cross-shard transaction: Örneğin bir e-ticaret sitesinde müşteri bilgileri bir shard altında sipariş detayları başka shard altında tutuluyorsa ve tek bir checkout işlemiyle her ikisi de güncelleniyorsa tercih edilebilir.
Sağlık kayıt sistemleri (hasta tedavi + ilaç + faturalandırma): Bir hastanenin farklı departmanları veya farklı kurumlar (SGK, özel sigorta, eczane) arasında tutarlı veri yazılması gereken işlemlerde kullanılır.
Enerji dağıtım şirketlerinin sayaç okuma ve faturalandırma entegrasyonu: Akıllı sayaç verilerinin farklı sistemlere (faturalama, ödeme, kesinti) aynı anda ve tutarlı şekilde işlenmesi gerektiği durumlarda düşünülebilir.
Bunun gibi örnekler çoğaltılabilir. 2PC mantığına uyan her şeyi düşünebilirsiniz.
Saga Pattern Yapısı
2PC’de merkezi bir transaction manager tüm servislerden yanıt beklerken, Saga’da böyle bir merkez yoktur. Her mikroservis kendi local transaction’ını kendi veritabanı üzerinde yönetir ve işlem başarılı olduğunda bir sonraki servisi tetikler. Böylece servisler uzun süreli lock altına girmez ve sistemde availability korunur.
Saga’da teorik olarak her adım bağımsız bir transaction olarak ele alnır. Bir servis kendi işini bitirdiğinde “ben tamamladım” anlamına gelen bir event veya mesaj yayınlar. Bu mesajı dinleyen bir sonraki servis kendi içinde transaction başlatır. Bu zincirleme yapı sayesinde distributed transaction ihtiyacı ortadan kalkar. Ancak bu model ACID’in atomicity garantisini otomatik olarak sağlamaz. Bir adım başarısız olursa önceki adımlar kendiliğinden geri alınmaz.
Saga Pattern’de en kritik teknik nokta, hata durumunda compensating transaction kavramıdır. Eğer zincirin herhangi bir adımında hata oluşursa daha önce başarıyla tamamlanmış işlemleri geri almak için ters işlemler yazmak gerekir. Bu rollback mekanizması framework tarafından otomatik sağlanmaz yani tamamen geliştiricinin sorumluluğundadır. Örneğin stok düşme başarılı olmuş ama ödeme başarısız olmuşsa, stoku tekrar artıran bir compensating işlem çalıştırılmalıdır. Dolayısıyla bu pattern tercih edilecekse geliştirmenin yönü buna göre olacaktır.
Bir sipariş sürecinde OrderService siparişi oluşturur ve OrderCreated eventi yayınlar. PaymentService bu eventi alır, ödemeyi alır ve başarılı olursa PaymentCompleted eventi yayınlar. Ardından DepositService bakiye düşer. Eğer PaymentService hata alırsa, OrderService’e bir PaymentFailed event fırlatır ve OrderService siparişi iptal eden bir compensating transaction çalıştırır. Burada geri dönüş işlemleri tamamen açıkça tanımlanmıştır.
Saga Pattern’in iki türü bulunur: Choreography Based Saga ve Orchestration Based Saga.
Orchestration Based Saga
Orchestration Based Saga içinde tüm süreci yöneten bir Saga Orchestrator bulunur. Bu orchestrator teknik olarak bir servis ya da bir obje olabilir. Akışın hangi adımda olduğunu bilir ve sıradaki servise ne yapacağını söyler ve gelen cevaba göre bir sonraki adımı tetikler. Orchestration-Based düzeninde merkezi bir yapı vardır ve bu yapı tam anlamıyla orkestra şefi gibi davranır.
Orchestrator tüm iş akışını bilen tek bileşendir. Hangi adımın ne zaman çalışacağını o belirler. Servisler birbirleriyle konuşmaz, sadece orchestrator ile konuşur. Hangi adımda hata olduğunu bilirsiniz, hangi compensating transaction çalışacağını bilirsiniz. Sırada kim ne yapacak sorularının cevabı tek merkezdedir.
Aşağıda Saga Orchestrator aracılığıyla yapılan işlemlerin takibini görebilirsiniz.
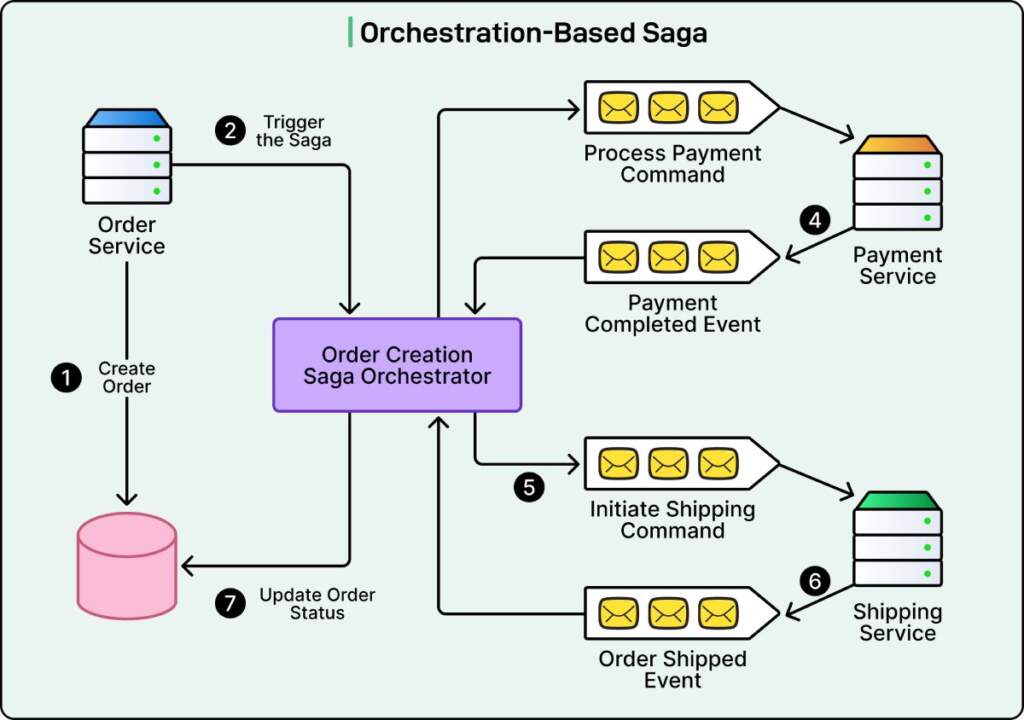
Görsel: ByteByteGo
Bu yapıda kullanılacak basit bir örnek yapalım. Saga oluşturalım.
public class UserRegistrationSaga
{
private readonly UserService _userService;
private readonly EmailService _emailService;
public async Task Start(RegisterUserRequest request)
{
try
{
// 1. User create
var userId = await _userService.CreateUser(request);
// 2. Mail notice
await _emailService.SendWelcomeMail(userId);
}
catch (Exception)
{
// Compensating action
await _userService.DeleteUser(request.Email);
throw;
}
}
}Saga içinde kullanılan servislere değinelim:
public class UserService
{
public async Task<Guid> CreateUser(RegisterUserRequest request)
{
var user = new User(request.Email);
_repository.Add(user);
await _unitOfWork.CommitAsync();
return user.Id;
}
public async Task DeleteUser(string email)
{
_repository.DeleteByEmail(email);
await _unitOfWork.CommitAsync();
}
}
public class EmailService
{
public Task SendWelcomeMail(Guid userId)
{
return Task.CompletedTask;
}
}Şimdi bu yapıda ne görüyoruz? Akış tek yerde ve servisler sadece “yap” denileni yapıyor. Rollback merkezi bir yapı. Bu pattern sıralı akışlarda, rollback gerektiren yerlerde, debug ve trace çok önemliyse doğru bir tercih olur. İş aklı tek yerde olsun ve servisler sadece uygulayıcı olsun diyorsanız tercih edilebilir.
Choreography Based Saga
Merkezi yönetici olmadan event-driven yaklaşımdır. Choreography Based Saga içinde bir orchestrator veya manager yoktur. Servisler tamamen event-driven çalışır ve birbirlerine doğrudan mesaj gönderir. Her servis ilgilendiği event kanalını dinler ve kendi local transaction işlemini çalıştırır. Yani burada servisler kendi aralarında koreografi yapıyor gibi.

Görsel: ByteByteGo
Bu örnekte saga event zinciriyle ilerliyor. Bu yaklaşım gevşek bağlı (loosely coupled) ve ölçeklenebilir bir yapı sunar. Ancak süreç takibi tek bir yerde görülmez. Yani akış farklı servislerin içine dağılmıştır. Debug etmek, izlemek ve hatayı nerede aldığını anlamak zorlaşır. Sistem büyüdükçe event spagetti riski ortaya çıkar.
İş akışı doğal olarak event-driven ise choreography çok uygundur. Örneğin bir kullanıcı sisteminize kayıt oldu varsayalım. UserRegistered event oluşturuyorsunuz.
public record UserRegisteredEvent(
Guid UserId,
string Email,
DateTime RegisteredAt
);“UserService” kayıt işlemi yapar:
public async Task RegisterUser(RegisterUserRequest request)
{
// Local transaction
var user = new User(request.Email);
_userRepository.Add(user);
await _unitOfWork.CommitAsync();
// Event publish
var evt = new UserRegisteredEvent(
user.Id,
user.Email,
DateTime.UtcNow
);
await _eventBus.PublishAsync(evt);
}Dikkat: “UserService” kimleri tetiklediğini bilmez.
“EmailService” kendisine hoşgeldin e-posta bildirimi için mail gönderir.
public class UserRegisteredEmailHandler
{
public async Task Handle(UserRegisteredEvent evt)
{
await _emailSender.SendAsync(
evt.Email,
"Welcome!",
"Welcome to Recep Serit's newsletter!"
);
}
}Hiçbiri birbirini bilmez. Sadece event dinler.
Bu yapı ne zaman kullanılmalı? Side-effect işlemleriniz varsa, iş akışınız basitse, projenizde eventually consistency kabul ediliyorsa çok iyi bir tercih olur.
Rollback gerektiren, bir adım bitmeden diğeri başlayamaz dediğiniz senaryolar, finansal süreçlerde yanlış bir tercih olur.
Sonuç
Microservice mimarisinin sunduğu esneklik ve ölçeklenebilirlik avantajlarının karşılığında gelen en zor problemlerden biri transaction yönetimidir. Monolitik yapılarda alışık olduğumuz ACID garantileri ve tek transaction konforu, servisler ve veritabanları ayrıldığında doğrudan uygulanamaz hale gelir. Bu noktada geliştiricinin önündeki temel şey “bu yapı ne seviyede tutarlı olmalı?” sorusudur.
Sonuç olarak dağıtık transaction yönetimi için her duruma uyan tek doğru çözüm yoktur. Her transaction işlemini bölmeden önce, gerçekten güçlü bir consistency için ihtiyaç olup olmadığı sorgulanmalıdır. Eventual consistency kabul edilebiliyorsa Saga gibi yaklaşımlar tercih edilmeli ancak kabul edilemiyorsa belki de o operasyonun en baştan dağıtık hale getirilmemesi daha doğru bir mimari karar olacaktır.




1 Yorum