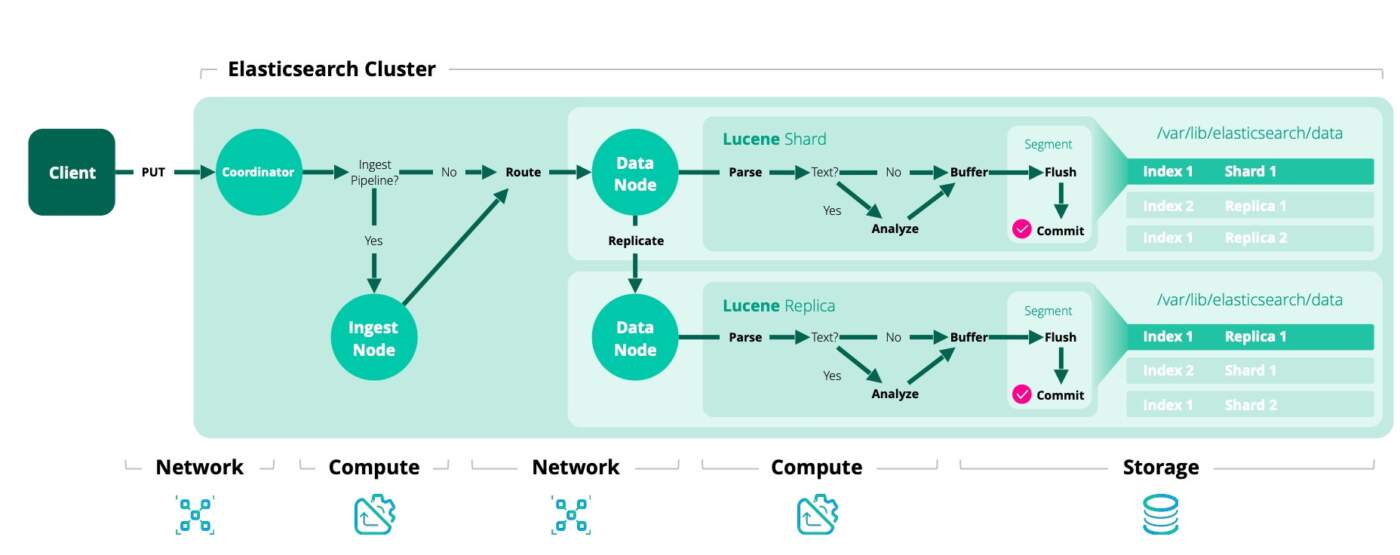
Elasticsearch’e gönderilen her döküman, arama performansını en üst düzeye çıkarmak ve doğru sonuçlar üretebilen bir indeks yapısı oluşturmak için, indekslenmeden önce çeşitli işlemlerden geçirilir. Bu işlemler toplu olarak “Analysis” (analiz) süreci olarak adlandırılır ve bu süreci yöneten bileşene ise Analyzer denir.
Basit bir log arama işlemi için özel bir analyzer oluşturmanıza gerek yok ancak uzun metinler ve binlerce döküman arasından en ilgili olanı getirmek gibi dertleriniz varsa analyzer olmazsa olmazdır. Çünkü bir analyzer, döküman içeriğini analiz ederken bir dizi ardışık adım uygular ve bu adımlar sayesinde metin, Elasticsearch’ün arama sırasında daha verimli bir şekilde çalışabileceği bir forma dönüştürülür.
Analyzer temel akışu şu şekildedir:
- Text
- Character Filter
- Tokenizer
- Token Filter
- Index
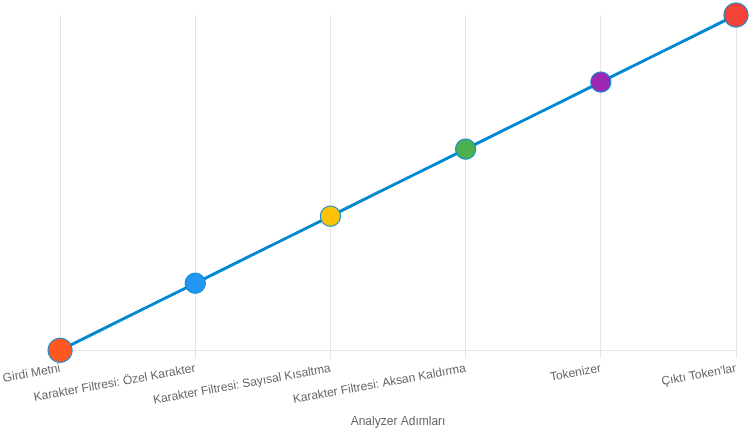
Karakter Filtreleme (Character Filtering)
Bu aşamada metindeki bazı karakterler daha tutarlı hale getirilir veya başka karakter dizileriyle değiştirilir. Amaç, arama sonuçlarını olumsuz etkileyebilecek karakter farklılıklarını ortadan kaldırmaktır.
Örnek metin:
I love u 2
you & me
Café
Filtreleme sonucu:
I love you too
you and me
Cafe
Bu aşama sayesinde kelimeler farklı yazılmışsa bile ilgili belgeleri de bulabilirsiniz.
Tokenlaştırma (Tokenization)
Bu aşamada metin küçük parçalara (token) bölünür. Token genellikle bir kelimeyi temsil eder ancak seçilen tokenizer türüne göre davranış değişebilir.
Metne karakter filtreleri uygulandıktan sonra döküman kelimelere ayrıştırılmalıdır. Bu aşamada devreye Lucene girer. Lucene, Java tabanlı güçlü bir bilgi erişim (information retrieval) kütüphanesidir ve Elasticsearch de arama motorunun temelini Lucene üzerine kurar. Lucene dökümanları olduğu gibi saklamak yerine, aramaları hızlandırmak için inverted index adı verilen bir veri yapısı kullanır.

Inverted index, her kelimenin geçtiği dökümanları hızlıca bulabilmemizi sağlar. Bu nedenle, Lucene dökümanı token adı verilen parçalara böler ve her token indekslenir. Örneğin standart bir tokenizer kullanıldığında cümle, boşluklar ve satır sonlarına göre kelimelere (token) ayrılır. Bu tokenlar ardından inverted index’e eklenir ve arama sırasında hızlı bir şekilde sorgulanabilir.

Örnek yapalım.
Girdi: “Analyzing Machine Learning & AI trends in 2025”
Standart Tokenizer Sonucu: [“analyzing”, “machine”, “learning”, “ai”, “trends”, “in”, “2025”]
Whitespace Tokenizer Sonucu: [“Analyzing”, “Machine”, “Learning”, “&”, “AI”, “trends”, “in”, “2025”]
Standart tokenizer, büyük/küçük harfleri normalize eder ve bazı noktalama işaretlerini atar. Örneğin “&” işareti çıkarılır ve “AI” ifadesi “ai” olur.
Whitespace tokenizer ise yalnızca boşluklara göre bölme işlemi yapar, bu nedenle “AI” ve “&” işareti olduğu gibi kalır.
Bu fark ise arama sonuçlarınızın hassasiyetini ve kapsamını doğrudan etkiler.
Token Filtreleme (Token Filtering)
Bu aşamada token işlenir, dönüştürülür veya filtrelenir. Birden fazla token filter aynı anda kullanılabilir.
Örnek filtre türleri:
lowercase: Tüm kelimeleri küçük harfe çevirir. “Merhaba” ifadesi “merhaba” oluyor. Ayrıca “the”, “is” gibi ifadeleri de kaldırıyor. Örneğin “the best analyzer” ifadesindeki “the” kaldırılır.
stemmer: Kök bulma işlemi yapar. Örneğin “running” kelimesinden “run” bulunur.
synonym: Eş anlamlı kelimeleri eşler. Örneğin “fast” diye arattığınızda dökümanda “quick” yazan kelimeyi eşleştirir.
Bu filtreler sayesinde aramalar daha esnek ve akıllı hale gelir.
Token Indeks (Indexing Tokens)
Son aşamada token dizsi artık Lucene’in inverted index yapısına kaydedilir. Bu yapı sayesinde Elasticsearch, bir kelimenin geçtiği tüm dökümanları hızlıca bulabilir.
Örneğin “tsql” kelimesi indekslenmişse, Elasticsearch o kelimeyi içeren tüm belgeleri anında döndürebilir. Buna ait örnek görseli “tokenization” kısmında gösterdim.
Analyzer bu bileşenlerden oluşur: Character Filters + Tokenizer + Token Filters.

Dökümanlarda Analyzer Kullanımı ve Yönetimi
Bir analyzer tanımlamanın temel olarak iki farklı yöntemi bulunmaktadır:
Index Bazlı (Custom Index Settings) Tanımlama: Analyzer bir indeks oluşturulurken veya mevcut bir indeks kapalı (closed) durumdayken, o indekse özel bir yapılandırma olarak eklenebilir.
Bu yaklaşım her indekse özgü, yüksek derecede esnek ve özelleştirilmiş analiz zincirleri (filter vs.) oluşturmanıza olanak tanır.
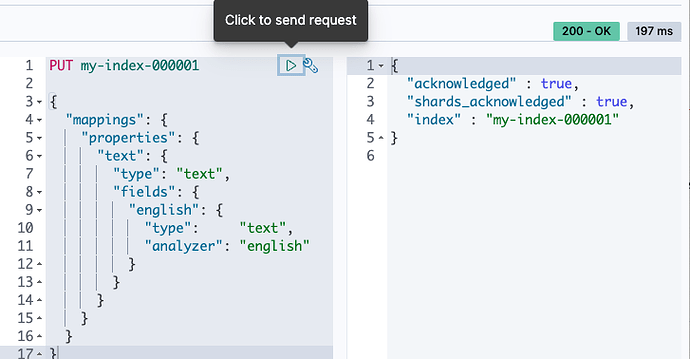
Global Configuration: Analyzer, Elasticsearch kümesinin konfigürasyon dosyasına (elasticsearch.yml) özel bir global ayar olarak eklenebilir.
Tüm index verileri tutarlı bir şekilde kullanacağınız ve sıkça değiştirmeyeceğiniz standart bir analizör setiniz varsa, bu yöntemi kullanarak her indeksin ayarlarını tek tek tanımlama yükünden ve potansiyel bant genişliği kullanımından tasarruf edebilirsiniz.
Built-In Analyzer Çeşitleri
Elasticsearch içinde farklı kullanım senaryolarına uygun ön tanımlı analyzer seçenekleri sunar.
- Standard Analyzer: Default (varsayılan) analyzer’dır; eğer özel bir analyzer belirtilmezse kullanılır. İçerdiği bileşenler: lowercase token filter ve stop token filter. Genel amaçlı ve Avrupa dilleri için uygundur.
- Simple Analyzer: Basit bir yapıdadır. Lowercase tokenizer kullanır. Tokenlar, harf olmayan karakterlere göre bölünür ve otomatik olarak küçük harfe çevrilir.
- Boşluk bazlı ayrıştırmayı kullanmaz, bu nedenle Asya dilleri için uygun değildir.
- Whitespace Analyzer: Metni yalnızca boşluklara (whitespace) göre böler. Başka bir işlem yapmaz, noktalama ve harf büyük/küçük durumunu değiştirmez.
- Stop Analyzer: Simple analyzer gibi davranır ancak ek olarak stop word’leri token stream’den çıkarır. Aramayı anlamsız kelimelerden arındırmak için kullanılır.
- Keyword Analyzer: Tüm alanı tek bir token olarak alır. Tokenization yapılmadan, tüm text üzerinde işlem yapmak istendiğinde idealdir.
- Pattern Analyzer: Tokenlar için özel pattern (regex) belirlemeye izin verir. Gelişmiş ayrıştırma senaryolarında kullanışlıdır.
- Snowball Analyzer: Standard tokenizer ve lowercase token filter ile stop filter kullanır. Kelime köklerini (stemming) çıkarma ve genel text normalizasyonu sağlar.
- Language – Multilingual Analyzer: Belirli bir dile özel tokenization ve token filtreleme sağlar. Daha sonra Türkçe analyzer kullanımıyla farklı bir örnek yapacağız. Çok dilli dokümanlar için uygundur.
Built-In Tokenizer Çeşitleri
Tokenization, metni küçük parçalara (tokenlara) ayırma işlemidir. Elasticsearch, farklı tokenizer çeşitleri sunar:
Standard Tokenizer: Grammar tabanlıdır ve Avrupa dilleri için uygundur. Noktalama işaretlerini otomatik olarak siler.
Örnek:
Girdi: “I have, cucumbers.”
Çıktı: [“I”, “have”, “cucumbers”]
Keyword Tokenizer: Tüm metni tek bir token olarak alır ve token filter uygulanabilir. Tokenization yapılmadan text üzerinde işlem yapmak istediğinizde kullanışlıdır.
Örnek:
Girdi: “hi, there”
Çıktı: [“hi, there”]
Letter Tokenizer: Metni harf olmayan karakterlere göre böler. Noktalama ve boşlukları tokenlardan ayırır.
Örnek:
Girdi: “Hi, there.”
Çıktı: [“Hi”, “there”]
Lowercase Tokenizer: Letter tokenizer + lowercase token filter birleşimidir. Tek adımda harf olmayan karakterlerden ayırma ve küçük harfe çevirme işlemi yapar.
Whitespace Tokenizer: Metni yalnızca boşluklara, tab veya satır sonlarına göre böler. Noktalama işaretlerini değiştirmez ve yalnızca boşluk bazlı ayrıştırma yapar.
Pattern Tokenizer: Tokenları ayırmak için özel regex pattern kullanmanıza izin verir.
Built-In Token Filter Çeşitleri
Token filter, tokenizer’dan çıkan tokenları işleyen, dönüştüren veya filtreleyen bileşenlerdir:
- Standard
- Lowercase
- Length
- Stop
- Trim
Stop filter için örnek verelim. İngilizce’de aşağıdaki kelimeleri token stream içinden kaldırır:
"a", "an", "and", "are", "as", "at", "be", "but", "by", "for", "if", "in", "into", "is", "it", "no", "not", "of", "on", "or", "such", "that", "the", "their", "then", "there", "these", "they", "this", "to", "was", "will", "with"N-gram ve Edge n-gram Yapıları
Ngram ve Edge Ngram, Elasticsearch’te metinleri tokenize etmenin özel yöntemlerindendir. Ngram, bir token öğesini eşit uzunlukta alt parçalara (subtoken) ayırır. Hem ngram hem de edge ngram kullanılırken oluşturulacak token öğelerinde minimum ve maksimum boyutlarını belirlemek için min_gram ve max_gram ayarları kullanılır.
Özellikle farklı dillerde olan ve uzun metinler sakladığınız kayıtları aramanız için net bir şekilde önerebileceğim bir tokenize yöntemidir. Hukuki dökümanlar için geliştirdiğim arama motorunda ilgili verileri daha hızlı ve yüksek skorla bulmaya başlamıştık.
N-gram: Örnek olarak “analytics” kelimesini ngram ile tokenize edelim:
- 1-grams: a, n, a, l, y, t, i, c, s
- Bigrams (2-grams): an, na, al, ly, yt, ti, ic, cs
- Trigrams (3-grams): ana, nal, aly, lyt,yti, tic, ics
min_gram ve max_gram değerlerini 2 ve 3 olarak ayarlarsak, elde edilen token dizisi şunlardır:
an, ana, na, nal, al, aly, ly, lyt, yt, yti, ti, tic, ic, ics, csBu yaklaşım aramalarda önemli bir avantaj sağlar. Örneğin kullanıcı “analitics” yazarsa, fuzzy query kullanmadan ngram token verileri sayesinde “analytics” ile eşleşme sağlanabilir:
- Bigrams for “analytics”: an, na, al, ly, yt, ti, ic, cs
- Bigrams for “analitics”: an, na, al, li, it, ti, ic, cs
Görüldüğü gibi, birçok token eşleşmektedir. Dolayısıyla arama esnek ve dil bağımsız hale gelir. Bu yöntem, birden fazla dil içeren veya dili bilinmeyen metinler üzerinde de etkili bir analiz sağlar.
Edge n-gram: Edge n-gram temel olarak n-gram’ın sadece kelimenin başından (prefix) tokenize edilen versiyonudur. Örneğin “database” kelimesi için min_gram:2 ve max_gram:5 ayarlarıyla oluşturulacak token dizisi şunlardır:
da, dat, datab, databa, databBu yapı prefix aramaları (prefix query) kullanmadan aynı öneki paylaşan kelimeleri hızlı bir şekilde bulmayı sağlar. Edge n-gram özellikle dil bilgisi olmayan veya bilinmeyen dillerde metin analizi için uygundur.
Shingles: Karakter yerine token seviyesinde n-gram üretir. Örneğin “cloud computing services” cümlesinde min_shingle_size: 2, max_shingle_size: 3 denediğinizde sonuç:
cloud computing, cloud computing services, computing servicesYalnızca çoklu token kombinasyonlarını istiyorsanız, output_unigrams: false ayarıyla tek token öğelerini hariç tutabilirsiniz.
Stemming: Stemming, kelimeleri köklerine veya temel formuna indirger. Bu işlem arama esnekliğini artırmak için önemlidir çünkü bazı durumlarda kelimenin çoğul veya türev halleri üzerinden arama yapmak gerekir.
Örnek “running” kelimesinin kökü run. Stemming sayesinde, “runner”, “ran” veya “runs” gibi türevlerle de eşleşme sağlanabilir. Bu yaklaşımla katı exact match yerine daha esnek ve kapsamlı arama sonuçları sunar.
Aratma yapacağınız dökümanların önemine göre kullanımı size kalmış. Hukuki döküman örneğini vermiştim. Türkçe döküman sakladığınızı düşünün. Stemming ile çok daha alakalı sonuçlar elde edilebilir. Tabi index yapılandırmanızda buna göre mapping oluşturulmalı.
Buradaki her konu ayrı ayrı ele alınabilecek kadar tekniktir. Farklı örnekler yaparak daha iyi anlaşılmasını sağlama niyetindeyim. Umuyorum faydalı olur.




Yorum bırakın