
Elasticsearch günümüzün en popüler tam metin arama motorlarından ve dağıtılmış analitik veri depolarından biridir. Yüksek ölçeklenebilirliği, esnekliği ve neredeyse gerçek zamanlı arama yetenekleri sayesinde geniş bir kullanıcı kitlesine sahiptir. AWS Elasticsearch Service (şimdiki adıyla Amazon OpenSearch Service), küme yönetiminin karmaşıklığını ortadan kaldırarak bu servisin kullanımını kolaylaştırır. Ancak bir üretim ortamında maksimum performansı elde etmek ve riskleri minimize etmek, özellikle küme, doküman, indeks ve sorgu konfigürasyonları hakkında derinlemesine ön bilgi gerektirir.
Yüksek Paralellik
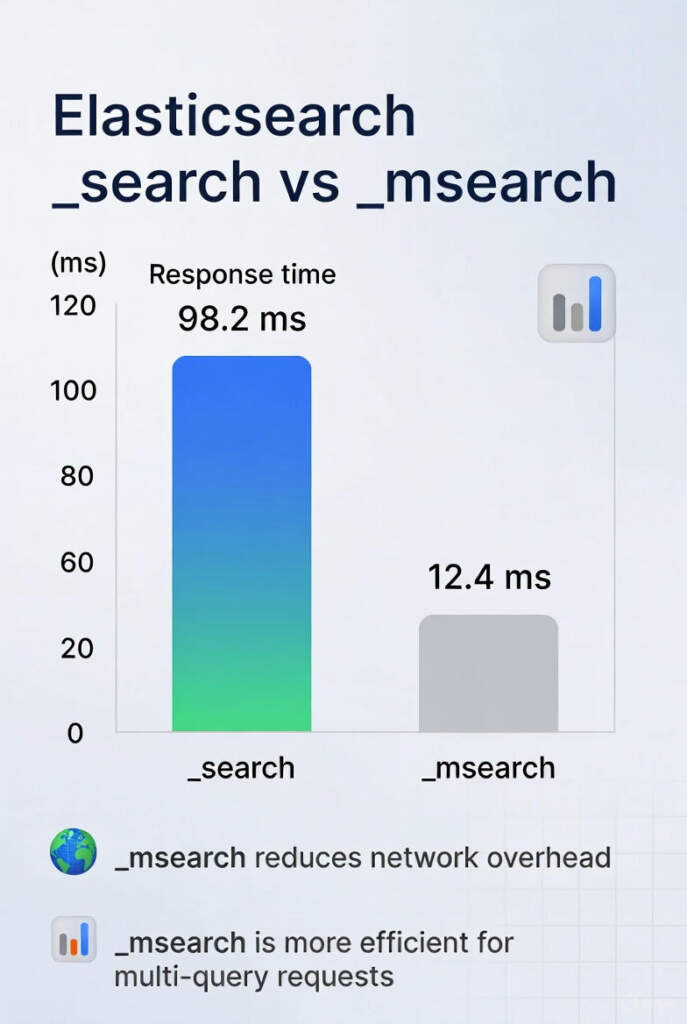
Yüksek hacimli ve düşük gecikmeli arama senaryolarında Elasticsearch’ten beklenen performansı elde etmek, çoklu sorgu yönetimi ve kaynak kapasitesi konularında daha çok tecrübe gerektiriyor. Performansı artırmak için çıkarılan temel teknik derslerden biri, birden fazla sorguyu tek bir ağ isteğiyle göndermeye olanak tanıyan toplu API olan _msearch kullanımının optimize edilmesidir.
Batch API (_msearch) kullanımı: _msearch, istemci ile küme arasındaki gidiş-dönüş süresini (roundtrip time) azaltarak ağ gecikmesini düşürür fakat bu sorgu süresini doğrudan garanti etmez, zira toplu isteğin tamamlanma süresi, içindeki en yavaş alt sorgunun bitiş süresine bağımlıdır. Bu nedenle en yüksek çıktıyı (throughput) elde etmek için, _msearch kullanımı istemci tarafındaki eşzamanlı isteklerle (concurrent requests) mutlaka birleştirilmelidir.
Concurrent Request + Batch API: Verimli bir arama için istemci uygulamasında eşzamanlı istekler (concurrent requests) ile _msearch API’si birlikte kullanılmalıdır. Yani birden fazla toplu isteği (her biri birden fazla alt sorgu içerir) aynı anda sunucuya göndermek, kümenin kaynaklarını daha etkin kullanır. Dolayısıyla işlem hızınız artar.
Sonuç boyutu belirleme: Sonuçlarında döndürülen belge sayısının (size parametresi) ve içeriğinin makul bir değerde ayarlanması gerekir. Gereğinden fazla veri getirmek, hem düğümün kaynak kullanımını hem de ağ bant genişliği tüketimini artırarak gecikmeyi yükseltir.
Eşzamanlı arama sınırı: Bir Elasticsearch veri düğümünün/örneğinin desteklediği eşzamanlı arama operasyonu sayısı [(Mevcut işlem sayısı x 3)/2] + 1 formülü ile belirlenir. Bu düğümün search thread pool boyutudur. Bu kapasiteyi aşan tüm istekler kuyruğa gönderilir. Kuyruk dolduğunda (overflow), yeni istekler reddedilir ve 429 Too Many Requests hataları alınır.
Örnek .yaml yapılandırması:
thread_pool.search.size: 20
thread_pool.search.queue_size: 2000Shard sayısı optimizasyonu: Elasticsearch kümesinde işlem çıktısını (throughput) maksimize etmek için parçaların (shards) veri düğümlerine (data nodes) optimal ve dengeli dağıtımı sağlanmalıdır. Her bir veri düğümünün (data node) üzerine düşen toplam parça sayısını (birincil ve replika parçalar dahil) makul bir seviyede tutmak ve tercihen her düğüme aynı sayıda parça düşmesini sağlamaktır. Elasticsearch sorguları (query) bir parçaya atar ve parça sorguyu işler. Eğer bir düğümün üzerinde çok fazla parça varsa o düğümün kaynakları aşırı yüklenir.
Caching kullanımı: Hem istemci tarafında verileri önbellekte tutmak (in-memory tercihen) hem de Elasticsearch tarafındaki kritik önbellekleri (field cache, request cache, query cache) etkinleştirmek gerekir. Bu tekrarlanan sorguların ve sık kullanılan veri yapıların hızlıca bellekten getirilmesini sağlar. Arama performansını epey arttıracaktır.
Önbellekleme (Caching) ve Sorgu Optimizasyonu
Performansın son ve belki de en önemli bileşeni önbelleklemedir. Hem istemci tarafında bellek içi önbellek (in-memory cache) kullanmak (örneğin sık ve değişmeyen sonuçları depolamak için) hem de Elasticsearch tarafındaki remote cache özelliklerini etkinleştirmek hayati önem taşır.
— Field Cache: Alan (field) verilerini bellekte tutarak sıralama ve toplama (aggregation) işlemlerini hızlandırır. Tabi bu cache seçeneği ES 5.x ve sonrası sürümlerde genellikle “heap” dışındaki OS cache tarafından yönetilen doc values ile değiştirilmiştir.
— Request Cache: Aynı sorguya ait tam sonuçları indeks/parça bazında önbelleğe alır. Özellikle sık tekrarlanan sorgular için gecikmeyi önemli ölçüde düşürür.
Aktifleştirmek için:
PUT /my-index-000001
{
"settings": {
"index.requests.cache.enable": false
}
}Dilerseniz request bazlı da yapabilirsiniz:
GET /my-index-000001/_search?request_cache=true
{
"size": 0,
"aggs": {
"popular_colors": {
"terms": {
"field": "colors"
}
}
}
}Shard request cache gayet anlaşılır bir doküman yayınlanmış: https://www.elastic.co/docs/reference/elasticsearch/rest-apis/shard-request-cache
— Query Cache: Filtre bağlamındaki (filter context) sorguların sonuçlarını önbelleğe alır. Bu toplama ve filtreleme işlemlerinde büyük performans artışı sağlar.
Bu teknik optimizasyonları birleştirmek ve doğru küme boyutlandırmasını yapmak, zorlu gecikme gereksinimleri olan yüksek hacimli sorgu senaryolarında dahi Elasticsearch kümesinin kararlı ve yüksek performanslı çalışmasını sağlamanın temelini oluşturur.
Optimal Sorgu Stratejileri: _msearch ve _search
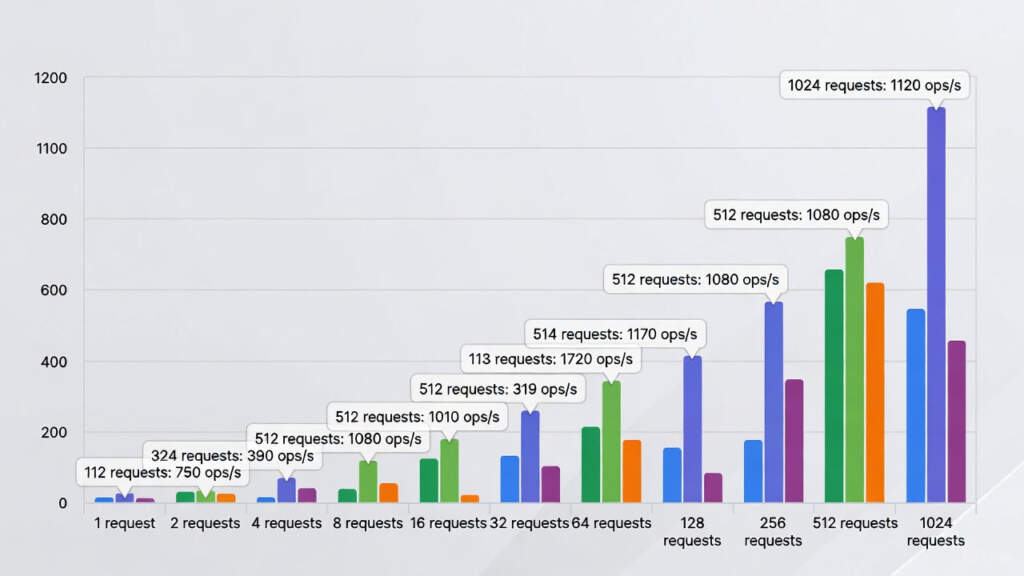
Elasticsearch’te yüksek sayıda arama isteği işlenirken, tek bir Bulk API (_msearch) mi kullanılmalı yoksa aynı anda birden fazla Single API (_search) mi gönderilmeli? Her ikisiyle de denemeler yaptım.
İlk deneyimde 30’dan fazla alt sorgu içeren tek bir _msearch isteği yaptım ancak tekli aramaya göre 2 kat daha yavaş çalıştı. Bulk API her zaman avantajlı değildir çünkü dezavantajları bulunur. _msearch en büyük dezavantajı, toplam yanıt süresini oluştururken içindeki en ağır çalışan alt sorgunun tamamlanmasını bekler. Eğer 30 sorgudan sadece biri kaynak tüketimi nedeniyle gecikirse tüm toplu yanıt gecikir.
Diğer yandan büyük bir _msearch isteği, Elasticsearch düğümüne ulaştığında tek bir işlem olarak algılanır. Bu potansiyel olarak search thread pool içinde tek bir kuyruk yuvasını işgal eder ancak tüm alt sorguların kaynakları eşzamanlı olarak kullanma talebini içerir. Eğer cluster bu ani yükü kaldıramazsa içerideki alt sorgular yavaşlar (buna throttling denir). Dolayısıyla arama isteği öncesinde cluster yapınızı ve verilerinizi iyi tanımalısınız.
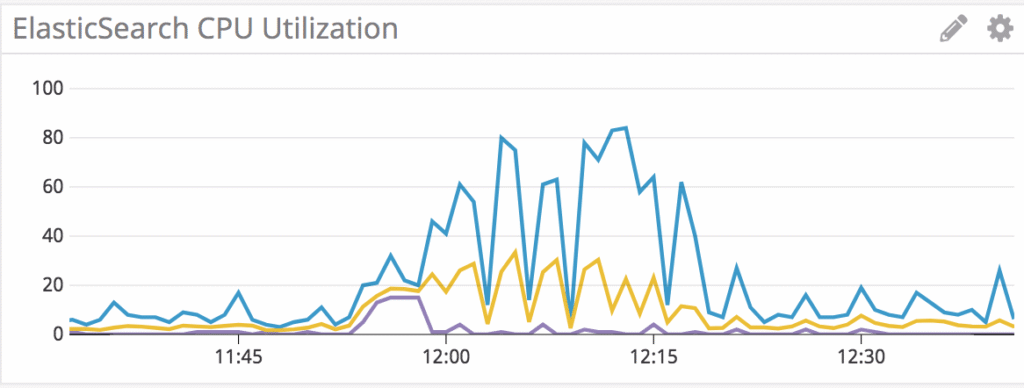
Sonuç olarak en verimli strateji, her iki yaklaşımın avantajlarını birleştiren hibrit modeldir: Büyük sorgu listesinin, her biri makul sayıda alt sorgu içeren küçük _msearch gruplarına (batches) bölünmesi ve bu _msearch gruplarının eşzamanlı olarak Elasticsearch kümesine gönderilmesidir.
Farklı _msearch grupları eşzamanlı olarak gönderildiği için (concurrent connections), kümedeki search thread pool farklı işlemleri paralel olarak işlenmeye başlar. Bu gecikmeyi azaltacaktır. Her bir _msearch içindeki alt sorgular, tek bir ağ isteği altında toplanarak ağ gecikmesi faydasını korur.
Bu yaklaşım ile birlikte tek bir devasa _msearch isteği göndermenin getireceği timeout riskini azaltır ve aynı anda yüzlerce bağımsız istek göndermenin Elasticsearch kümesini aşırı yükleme (throttling) riskini kontrol altına alır. Burada başarınızı arttırmak için, gruplara ayırma boyutunun (her _msearch içindeki alt sorgu sayısı) ve eşzamanlı gönderilen _msearch grubu sayısının, kümenizin CPU ve search thread pool kapasitesine göre doğru ayarlanması gerekmektedir.
Cluster Yapılandırma
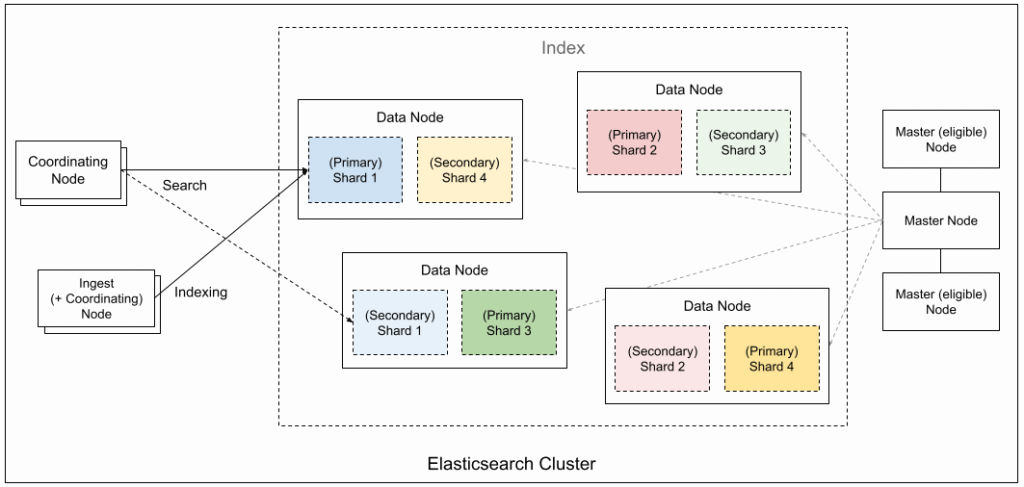
Performansı en üst düzeye çıkarmak için küme bileşenlerinin nasıl çalıştığını anlamak esastır. Elastic ekibinin yayınladığı dökümanları takip edin: https://www.elastic.co/docs
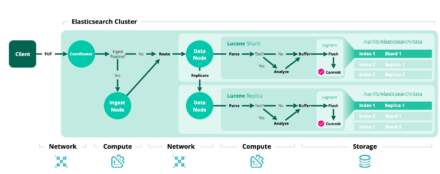
1– Shard ve Gecikme İlişkisi
Parça sayısı arttıkça, gecikme de artar. Her bir sorgunun tamamlanması için birden fazla parçaya isabet etmesi gerekir. Bu parçalar aynı düğümde bulunsa bile, Elasticsearch’ün koordinatör düğümünün (coordinator node) parçalardan gelen sonuçları birleştirmesi (scatter/gather süreci) ve potansiyel olarak farklı düğümlerdeki parçalar arasında ek ağ iletişimi kurması gerekir. Bu ek yönetim ve iletişim yükü gecikmeyi artırır. Ancak bir parçanın ideal boyutu genellikle 50 GB’ın altında olmalıdır. Veri boyutunuz bu değeri aşmıyorsa, aktif indeksiniz için yalnızca 1 birincil parça bulundurmak performansı optimize etmeye yardımcı olur.
2– Replica Sayısının Belirlenmesi
Replika sayısı arttıkça gecikme (latency) düşer. Bu kuralın anlaşılması oldukça basittir. Replika (kopya) parçalar, birincil parçanın (primary shard) tam kopyalarıdır ve arama isteklerini işlemek için kullanılabilirler. Daha fazla replika varsa veriyi okumak için küme genelinde daha fazla servis noktası (okuma kapasitesi) anlamına gelir. Arama yükü bu replikalar arasında daha iyi dağıtılır ve bu da ortalama sorgu süresini ve gecikmeyi azaltır.
3– Shard ve Node Sayılarının Eşitlenmesi
Primary shards + replika sayısını (toplam parça sayısı) node sayısıyla aynı tutun. Her bir veri düğümüne yalnızca bir parça düşmesini sağlamaktır. Bu kural biraz daha maliyetlidir. Bu sağlandığında bir node içindeki tüm iş parçacığı (thread pool) kaynaklarının, o düğümdeki tek bir parçanın isteğine hizmet etmek için tamamen tahsis edilmesini sağlar. Böylece düğümün yerel kaynakları (CPU, bellek) en verimli şekilde kullanılır.
4– CPU Çekirdek Sayısının Arttırılması
Her node içindeki CPU çekirdeği sayısı arttıkça gecikme düşer. Bu doğrudan bir ilişkidir. Bir düğümün destekleyebileceği eşzamanlı arama isteği sayısı, büyük ölçüde işlemci çekirdeği sayısına bağlıdır. Daha fazla çekirdek, search thread pool boyutunun daha büyük olmasını ve dolayısıyla daha fazla isteği aynı anda işleyebilmesini sağlar.
Sonuç olarak, optimum Elasticsearch performansı, doğru küme boyutlandırması (CPU/çekirdek sayısı, parça dağıtımı) ile akıllı istemci tarafı sorgu yönetiminin (hibrit _msearch kullanımı) birleşimiyle sağlanır. Performansın sürekli takibi ve parametrelerin iş yüküne göre hassas ayarı, bu kompleks sistemlerin sürdürülebilir başarısı için anahtardır. Umarım faydalı olmuştur.


Yorum bırakın